*better: More thorough, more relevant, more effective.
...more Alerts, more All Clears, more details, more control in your hands.
|
|
Foxhound is the better* Database Monitor for SQL Anywhere.
*better: More thorough, more relevant, more effective.
...more Alerts, more All Clears, more details, more control in your hands.
|
Breck Carter
Last modified: October 18, 1996
mail to: bcarter@bcarter.com
[Home]
How can I read and scan data from a flat file into a SQL Anywhere 5 database?
Figure 1 shows an example of a flat text file that contains the results of a CompuServe stock price query. It contains three kinds of lines:
Issue: otexf
(D)aily, (W)eekly, (M)onthly? : d
Starting date or number of
periods from last pricing date? 1/1/96
...
Issue OTEXF has prices from
1/24/96 through 10/11/96
Do you want to:
1 Report 188 days between
1/24/96 and 10/11/96
...
Enter choice !1
OPEN TEXT CORP
COM
Cusip: 68371510 Exchange: K Ticker: OTEXF
Date Volume High/Ask Low/Bid Close/Avg
--------- ---------- ---------- ---------- ----------
1/24/96 4,666,000 26 1/2 21 1/4 22
1/25/96 1,116,000 22 1/2 19 11/16 20 3/4
1/26/96 486,000 20 3/4 19 19 7/16
1/29/96 438,500 19 3/4 17 1/2 17 3/4
...
OPEN TEXT CORP
COM
Cusip: 68371510 Exchange: K Ticker: OTEXF
Date Volume High/Ask Low/Bid Close/Avg
--------- ---------- ---------- ---------- ----------
2/12/96 109,700 19 1/4 18 3/32 18 3/4
2/13/96 67,300 19 17 7/8 18 3/8
...
LYCOS INC
COM
Cusip: 55081810 Exchange: K Ticker: LCOS
Date Volume High/Ask Low/Bid Close/Avg
--------- ---------- ---------- ---------- ----------
4/02/96 5,882,000 29 1/4 21 3/4 21 15/16
4/03/96 1,199,000 22 1/2 20 1/4 20 1/4
4/04/96 1,088,000 21 16 1/2 18
4/05/96 0 HOL HOL HOL
...
|
Heading lines may be repeated for the same stock when there are many detail lines. Information for different stocks may also appear in the same file and when that happens, the heading lines change.
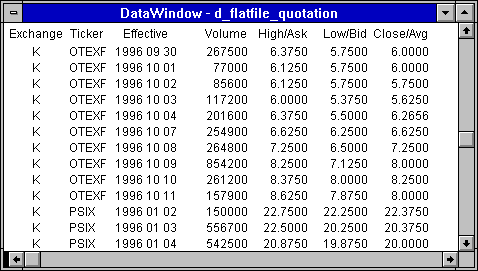
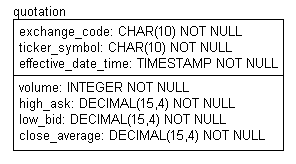
Figure 2 shows where this data is to go. Somehow matching detail and heading lines must be combined and the other input lines must be ignored. Not only that, but the detail lines contain strange fields like "18 3/32" which must be converted into decimal numbers. And "HOL" which must be ignored.
Figure 2: The Final Quotation Table
 |
It might be possible to use an ODBC text driver to deal with this file but it doesn't seem to be a good match in this case... too many limitations, and it only solves part of the problem. And besides, I didn't think of it at the time.
Another more common approach is to read the file into a PowerBuilder program and write PowerScript code to scan and load the quotation table. Sometimes that works well, sometimes it can be dog slow. And it violates the "Flat Files In SQL" title which implies we're going to stick to SQL when solving this problem.
At the very least "sticking to SQL until it becomes impossible" can lead to new ideas and techniques that might be useful later. And sometimes these new ideas are immediately useful. So here goes:
Figure 3 shows the first step: Use SQL Anywhere's rocket-fast Load Table command to read the file as-is into the simple table shown in Figure 4.
Figure 3: Loading Data As-Is
// Delete existing raw input. delete from raw_input\ // Load raw CompuServe data. load table raw_input from 'e:\\amisc\\invest\\fin1cser.txt' format 'ascii' delimited by '\x00' strip off quotes off escapes off\ |
Figure 4: The As-Is Data Table
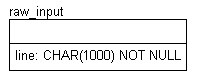 |
The Load Table parameters were chosen to prevent SQL Anywhere from making any changes to the data as it's read in. For example, the field delimiter was set to the zero byte because that character doesn't appear in the input. For more information about this command, see the Help file \sqlany50\win\dbeng50w.hlp.
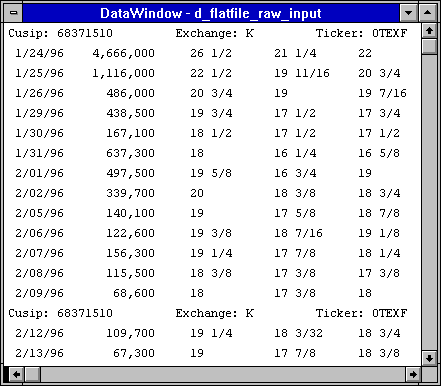
Figure 5 shows how easy it is to get rid of all the uninteresting rows with a single set-oriented delete. The result is shown in Figure 6.
Figure 5: Deleting Uninteresting Rows
// Get rid of uninteresting lines, keeping only
// the Cusip/Ticker heading lines, and the
// detail lines starting with "mm/dd/yy..."
// that aren't also marked as holidays or are
// "through" ranges.
delete from raw_input
where substr ( line, 1, 7 ) <> 'Cusip: '
and ( ( substr ( line, 3, 1 ) <> '/' )
or ( substr ( line, 21, 9 ) = '0 HOL' )
or ( substr ( line, 9, 9 ) = ' through ' ) )\
|
Figure 6: Interesting Input
The raw_input table has one huge problem: No primary key. That must be rectified before any further processing is done, by copying all the data from raw_input to the numbered_input table shown in Figure 7.
Figure 7: Numbered Input
 |
The copy operation will automatically assign values to the line_number column because it has the new AutoIncrement default.
One problem with AutoIncrement, however, is that it's difficult to get SQL Anywhere to "start over at 1" when re-loading a table like numbered_input. The current maximum value of an AutoIncrement column appears to be loaded whenever the database is started, and removing and re-adding the AutoIncrement default doesn't reset this value. The result is that even when all the old rows are deleted, new rows receive continuously increasing values.
Figure 8 shows how to avoid this "Auto-Creep" problem by dropping and re-creating the numbered_input table before copying from raw_input. If you don't care about starting over at 1, this code can be simplified: Don't drop and re-create, just delete all the old rows.
Figure 8: Adding Line Numbers
// Drop and recreate numbered input to
// reset line numbering. This may be
// the only way to prevent "Auto-Creep".
drop table numbered_input\
create table numbered_input
( line_number integer default AutoIncrement not null,
line char ( 1000 ) default '' not null )\
alter table numbered_input
add primary key ( line_number )\
create index XIE1numbered_input
on numbered_input ( line ASC )\
// Copy to numbered table.
insert into numbered_input ( line )
select line
from raw_input\
|
Figure 8 also shows that an index is defined on the line column. This made a vast improvement in the next step, shown in the pseudo-code of Figure 9: Merge the heading and detail lines from numbered_input into the final quotation table.
Figure 9: Pseudo-SQL For Loading Quotation
insert into quotation
select various columns from the "a" row
from numbered_input a,
numbered_input b
where the "a" row is a detail row
and the "b" row is a heading row
and the "b" line number is the largest heading line number
that is less than the "a" detail line number.
|
The actual SQL in Figure 10 is a bit more complex than the pseudo-code. The most important part is in the where clause: A correlated sub-select that matches the correct heading rows with the corresponding detail rows. This sub-select slows things down a bit but the index described earlier helps a lot.
Figure 10: Actual SQL For Loading Quotation
// Get rid of current quotations.
delete from quotation\
// Load quotation with CompuServe data as follows:
// Merge data from Cusip/Exchange/Ticker rows
// with related quotation rows, calling functions
// to convert dates, volumes and fraction dollar
// amounts.
insert into quotation
select trim ( substr ( b.line, 35, 9 ) ) as this_exchange_code,
trim ( substr ( b.line, 53, 10 ) ) as this_ticker_symbol,
convert_date_time
( 'mm/dd/yy', substr ( a.line, 1, 8 ) ),
convert_volume
( substr ( a.line, 10, 12 ) ),
( cast ( trim ( substr ( a.line, 23, 6 ) )
as decimal ( 15, 4 ) )
+ convert_fraction
( substr ( a.line, 30, 5 ) ) ),
( cast ( trim ( substr ( a.line, 35, 6 ) )
as decimal ( 15, 4 ) )
+ convert_fraction
( substr ( a.line, 42, 5 ) ) ),
( cast ( trim ( substr ( a.line, 47, 6 ) )
as decimal ( 15, 4 ) )
+ convert_fraction
( substr ( a.line, 54, 5 ) ) )
from numbered_input a,
numbered_input b
where substr ( a.line, 1, 7 ) <> 'Cusip: '
and substr ( b.line, 1, 7 ) = 'Cusip: '
and a.line_number > b.line_number
and b.line_number =
( select max ( c.line_number )
from numbered_input c
where a.line_number > c.line_number
and substr ( c.line, 1, 7 ) = 'Cusip: ' )\
|
Figure 10 also shows three new user-defined functions that convert the input date, volume and fractional dollar fields. The SQL for these functions is shown in Figures 11, 12 and 13.
Figure 11: Convert_Date_Time Function
create function convert_date_time
( as_format char ( 50 ),
as_date char ( 50 ) )
returns timestamp
begin
declare ls_mm char ( 2 );
if lower ( as_format ) = 'mm/dd/yy' then
// Convert string 'mm/dd/yy' to a timestamp.
if substr ( as_date, 1, 1 ) = ' ' then
set ls_mm = substr ( as_date, 2, 1 );
else
set ls_mm = substr ( as_date, 1, 2 );
end if;
return DateTime
( '19'
|| substr ( as_date, 7, 2 )
|| '-'
|| ls_mm
|| '-'
|| substr ( as_date, 4, 2 )
|| ' 00:00:00' );
elseif lower ( as_format ) = 'yyyymmdd' then
// Convert string 'yyyymmdd' to a timestamp.
return DateTime
( substr ( as_date, 1, 4 )
|| '-'
|| substr ( as_date, 5, 2 )
|| '-'
|| substr ( as_date, 7, 2 )
|| ' 00:00:00' );
else
// Error.
return null;
end if;
end\
|
Figure 12: Convert_Volume Function
create function convert_volume
( as_volume char ( 12 ) )
returns integer
begin
// Convert string "999,999,999" to an integer.
declare ls_volume char ( 12 );
declare li_pos integer;
set ls_volume = as_volume;
set li_pos = locate ( ls_volume, ',' );
while li_pos > 0 loop
set ls_volume = left ( ls_volume, li_pos - 1 )
|| substr ( ls_volume, li_pos + 1 );
set li_pos = locate ( ls_volume, ',' );
end loop;
return cast ( ls_volume as integer );
end\
|
Figure 13: Convert_Fraction Function
create function convert_fraction
( as_fraction char ( 5 ) )
returns decimal ( 15, 4 )
begin
// Convert fraction "99/99" to a decimal.
declare ls_fraction char ( 5 );
declare li_pos integer;
set ls_fraction = trim ( as_fraction );
if ls_fraction = '' then
return 0;
end if;
set li_pos = locate ( ls_fraction, '/' );
return
cast ( left ( ls_fraction, li_pos - 1 )
as decimal ( 15, 4 ) )
/ cast ( substr ( ls_fraction, li_pos + 1 )
as decimal ( 15, 4 ) );
end\
|
Figure 14 shows the final result: Quotation rows with data from both heading and detail lines. And it was all done with SQL that could probably be buried inside a stored procedure running on the server.
Figure 14: The Final Quotation Data