Breck Carter
Last modified: July 22, 1996
mail to: bcarter@bcarter.com
The last time I tried to make gravy the result was too watery, so I added some flour. Then it was too thick so in went more water. Now it was watery again, and tasteless too, so more flour and meat stock and mushrooms and spices were added. This cycle was repeated until I had a gallon of gruel and decided to give up cooking altogether.
Some time ago I helped optimize a PowerBuilder application designed to solve a similar problem, "If we put this in the pot, what will be the result?" The pot was a smelter and the things that went into it were pieces of metal alloy of varying but known composition. For example, if 100 kilograms of alloy containing 98.5% aluminum were added to 100 kilograms of 99.5% aluminum, the result would be 200 kilograms that was 99% pure.
No one needs a computer to solve an example that simple, but in real life they were adding many pieces to the pot, each containing up to 26 different elements in varying proportions. These pieces came from different sources, all the way from pure hot metal to recycled scrap, plus the mysteriously named “heels”, “sows”, “pucks” and “logs”. Each piece was weighed and its composition was analyzed and stored in a database so that the final composition of a batch containing all these pieces could be calculated ahead of time.
This calculation was important because each batch had a customer who was expecting a specific target composition. The final result was analyzed too, but if it wasn’t right, and if the pot was now full of metal, some would have to be poured out and other pieces added in a second attempt to get it right. While they would save these outpourings to use as raw material for future batches (unlike the gravy I poured down the drain to make room for more flour), it was regarded as a waste of time and energy.
All these calculations had to be done in more-or-less real time by users standing next to fuming pots of molten metal, and they wanted to know if the pieces they’d chosen would produce success. The trouble was that it was taking several minutes for the PowerBuilder application to spit out the answer. And that’s where I came in, in my role as Forensic Programmer.
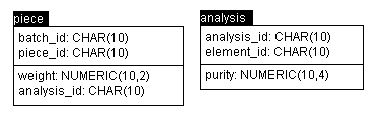
Figure 1 shows a simplified view of the piece and element tables. Each row in the piece table is identified by the batch and piece within the batch, and contains the piece’s weight and an field identifying its chemical analysis. The analysis table is keyed by analysis id and element (aluminum, iron, etc.), and each row contains the proportion (purity) of that element as measured by this particular analysis process. In the simple example above, the piece table would contain two rows with the same batch id but different piece ids, weights and analysis ids. The analysis table would contain rows with two different analysis ids (for the two different pieces), and one row for each element found in each piece.
Figure 1: Piece and Element Analysis Tables
For various (and legitimate) reasons, embedded SQL was used instead of DataWindows to retrieve this information. A straightforward row-oriented approach had been used: for each piece, the analysis table was queried for each element that was required in the final composition. If that element existed in this piece, its proportion in the piece was used to adjust the final proportion. Missing elements were treated as “zero purity” and also affected the final composition.
So where was the time going? Two nested cursor fetch loops were used, one using Format 3 dynamic SQL to get the pieces and the other Format 4 to look for elements. I don’t know about you, but outside of the PowerBuilder sample application I’d never even seen Format 4 SQL let alone used it myself. So it took a while before I noticed something even more unusual: the Format 4 cursor was being opened and closed with each fetch, 26 times, inside the inner “get next element for this piece” loop.
In other words, the inner fetch was based on a singleton select rather than a result set. Common sense indicated that a single result set containing 10 elements (a common number) would be more efficient 26 separate selects of which 10 would return a single row and the other 16 fail. A simple timing test proved that while Format 4 SQL might be very powerful, using it to seek individual rows can consume a lot of time.
Listing 1 shows a sample of code that was used to measure the time taken before and after optimization. Listing 2 shows the pseudo-code for the original nested-fetch implementation, and Listing 3 shows a simplified but working version of the actual code. The word “simplified” might seem too strong a term because it’s still pretty complex stuff; nevertheless, the actual script contained even more logic that’s been removed for the purpose of this article.
Listing 1: Measuring CPU Time
long ll_start_msec
long ll_elapsed_msec
ll_start_msec = CPU()
...long running script code
ll_elapsed_msec = CPU() - ll_start_msec
MessageBox ( "Time", &
string ( ll_elapsed_msec, &
"#####0" ) + " msec." )
Listing 2: Nested Fetch Pseudo-Code
outer cursor = select weight, analysis_id
from piece where batch_id = ?
inner cursor = select purity from analysis
where analysis_id = ? and element_id = ?
open outer cursor
fetch first row from outer cursor
do while there is another row
accumulate batch weight
for each of 26 elements of interest
open inner cursor // OUCH!!!
fetch single row from inner cursor
if fetch worked
accumulate element proportion
else
adjust proportion downwards
end if
close inner cursor // OUCH!!!
next
fetch next row from outer cursor
loop
close outer cursor
Listing 3: Nested Fetch Script
// Function Arguments:
// string as_batch_id
// The batch of interest.
// string as_element_id[]
// The 26 elements of interest.
// decimal ac_total_weight
// Accumulates the batch weight.
// decimal ac_total_purity[]
// Accumulates element proportions.
DynamicStagingArea ldsa_piece
DynamicStagingArea ldsa_analysis
string ls_analysis_id
string ls_piece_select
string ls_analysis_select
decimal lc_piece_weight
decimal lc_total_weight
decimal lc_piece_purity
decimal lc_total_purity
integer li_element_ctr
integer li_element_ct
// Outer cursor retrieves pieces in a batch.
ldsa_piece = create DynamicStagingArea
declare piece_cursor &
dynamic cursor for ldsa_piece;
ls_piece_select &
= "select weight, analysis_id " &
+ "from piece " &
+ "where batch_id = '" + as_batch_id +"'"
prepare ldsa_piece &
from :ls_piece_select using SQLCA;
// Inner cursor looks for a single element.
ldsa_analysis = create DynamicStagingArea
declare analysis_cursor &
dynamic cursor for ldsa_analysis;
ls_analysis_select &
= "select purity from analysis " &
+ "where analysis_id = ? " &
+ "and element_id = ?"
prepare ldsa_analysis &
from :ls_analysis_select using SQLCA;
describe ldsa_analysis into SQLDA;
// Start processing pieces.
open dynamic piece_cursor;
if ( SQLCA.SQLCode <> 0 ) &
and ( SQLCA.SQLCode <> 100 ) then
MessageBox ( "Error", "Open 1" )
halt close
end if
fetch piece_cursor &
into :lc_piece_weight, :ls_analysis_id;
if ( SQLCA.SQLCode <> 0 ) &
and ( SQLCA.SQLCode <> 100 ) then
MessageBox ( "Error", "Fetch 1" )
halt close
end if
do while SQLCA.SQLCode = 0
// Accumulate batch weight.
lc_total_weight = ac_total_weight
ac_total_weight &
= ac_total_weight + lc_piece_weight
// Look for elements in analysis.
SetDynamicParm ( SQLDA, 1, &
ls_analysis_id )
li_element_ct &
= UpperBound ( as_element_id )
// This is where the time is going...
for li_element_ctr = 1 to li_element_ct
SetDynamicParm ( SQLDA, 2, &
as_element_id [ li_element_ctr ] )
open dynamic analysis_cursor &
using descriptor SQLDA; // OUCH!!!
if ( SQLCA.SQLCode <> 0 ) &
and ( SQLCA.SQLCode <> 100 ) then
MessageBox ( "Error", "Open 2" )
halt close
end if
fetch analysis_cursor &
using descriptor SQLDA;
if ( SQLCA.SQLCode <> 0 ) &
and ( SQLCA.SQLCode <> 100 ) then
MessageBox ( "Error", "Fetch 2" )
halt close
end if
if SQLCA.SQLCode = 0 then
lc_piece_purity &
= GetDynamicNumber ( SQLDA, 1 )
else
lc_piece_purity = 0.0
end if
// Accumulate element proportion.
lc_total_purity &
= ac_total_purity[ li_element_ctr ]
ac_total_purity [ li_element_ctr ] &
= ( ( lc_total_purity &
* lc_total_weight ) &
+ ( lc_piece_purity &
* lc_piece_weight ) ) &
/ ac_total_weight
close analysis_cursor; // OUCH!!!
next
fetch piece_cursor &
into :lc_piece_weight, :ls_analysis_id;
if ( SQLCA.SQLCode <> 0 ) &
and ( SQLCA.SQLCode <> 100 ) then
MessageBox ( "Error", "Fetch 3" )
halt close
end if
loop
close piece_cursor;
destroy ldsa_piece
destroy ldsa_analysis
return
The original solution of Listings 2 and 3 may be stated as “Look for each element we want, and process the found and not-found cases similarly”. A new approach was worked out to involve a single result set: “Get all the elements we have, process them, then figure out what’s missing and adjust accordingly.” In other words, “Think sets, not rows!”, an important motto for anyone working with relational databases.
A second optimization was now possible: since the inner fetch loop was now using a result set, it could be combined with the outer fetch with a simple join. In other words, by joining the piece and analysis tables, a single Format 3 cursor could be used and the Format 4 SQL eliminated altogether.
As with all but the simplest optimizations, the down side was more complex script code. Extra logic was necessary to figure out which rows belonged to which piece, and to keep track of which elements were missing from each piece so their proportion in the final batch could be adjusted. Listing 4 shows the optimized pseudo-code, and Listing 5 shows the corresponding script.
Listing 4: Single Cursor Pseudo-Code
cursor = select piece_id, weight,
element_id, purity
from piece, analysis
where batch_id = ? and
piece.analysis_id = analysis.analysis_id
order by batch_id, piece_id
open cursor
fetch first row from cursor
do while there is another row
if it is a new piece
if it is not the first piece
figure out which elements were
missing from the previous piece
and adjust their proportions
end if
accumulate batch weight
end if
figure out which element was
found in this piece and
accumulate its proportion
loop
fetch next row from cursor
loop
if there was at least one piece
figure out which elements were
missing from the last piece
and adjust their proportions
end if
close cursor
Listing 5: Single Cursor Script
// - see Listing 3 for function arguments
DynamicStagingArea ldsa_piece
string ls_piece_select
decimal lc_piece_weight
decimal lc_total_weight
decimal lc_piece_purity
decimal { 6 } lc_total_purity
integer li_elem_ctr
integer li_elem_ct
string ls_piece_id
string ls_element_id
string ls_prev_piece_id
boolean lb_found[]
decimal lc_prev_piece_weight
decimal lc_prev_total_weight
boolean lb_not_done
li_elem_ct = UpperBound ( as_element_id )
// Single result set: piece AND element data.
ldsa_piece = create DynamicStagingArea
declare piece_cursor &
dynamic cursor for ldsa_piece;
ls_piece_select &
= "select piece_id, weight, " &
+ "element_id, purity " &
+ "from piece, analysis " &
+ "where batch_id = '" + as_batch_id &
+ "' and piece.analysis_id " &
+ "= analysis.analysis_id " &
+ "order by batch_id, piece_id"
prepare ldsa_piece &
from :ls_piece_select using SQLCA;
open dynamic piece_cursor;
if ( SQLCA.SQLCode <> 0 ) &
and ( SQLCA.SQLCode <> 100 ) then
MessageBox ( "Error", "Open" )
halt close
end if
fetch piece_cursor &
into :ls_piece_id, :lc_piece_weight, &
:ls_element_id, :lc_piece_purity;
if ( SQLCA.SQLCode <> 0 ) &
and ( SQLCA.SQLCode <> 100 ) then
MessageBox ( "Error", "Fetch 1" )
halt close
end if
ls_prev_piece_id = "" // no piece yet
do while SQLCA.SQLCode = 0
// Handle "break" on new piece.
if ls_prev_piece_id <> ls_piece_id then
// Anything missing in previous piece?
if ls_prev_piece_id <> "" then
for li_elem_ctr = 1 to li_elem_ct
// Adjust element proportion.
if not lb_found[li_elem_ctr] then
lc_total_purity &
= ac_total_purity &
[ li_elem_ctr ]
ac_total_purity &
[ li_elem_ctr ] &
= ( lc_total_purity &
* lc_prev_total_weight ) &
/ ( lc_prev_piece_weight &
+ lc_prev_total_weight )
end if
next
end if
// Accumulate batch weight.
lc_total_weight = ac_total_weight
ac_total_weight &
= ac_total_weight + lc_piece_weight
// Set up for this new piece.
for li_elem_ctr = 1 to li_elem_ct
lb_found [ li_elem_ctr ] = false
next
ls_prev_piece_id = ls_piece_id
lc_prev_piece_weight= lc_piece_weight
lc_prev_total_weight= lc_total_weight
end if
// Handle element that was found.
li_elem_ctr = 1
lb_not_done = true
do while lb_not_done
// Accumulate element proportion.
if ls_element_id = as_element_id &
[ li_elem_ctr ] then
lc_total_purity = ac_total_purity &
[ li_elem_ctr ]
ac_total_purity[ li_elem_ctr ] &
= ( ( lc_total_purity &
* lc_total_weight ) &
+ ( lc_piece_purity &
* lc_piece_weight ) ) &
/ ac_total_weight
lb_found [ li_elem_ctr ] = true
lb_not_done = false
else
li_elem_ctr++
if li_elem_ctr &
> li_elem_ct then
lb_not_done = false
end if
end if
loop
fetch piece_cursor &
into :ls_piece_id, :lc_piece_weight, &
:ls_element_id, :lc_piece_purity;
if ( SQLCA.SQLCode <> 0 ) &
and ( SQLCA.SQLCode <> 100 ) then
MessageBox ( "Error", "Fetch 2" )
halt close
end if
loop
// Anything missing in last piece?
if ls_prev_piece_id <> "" then
for li_elem_ctr = 1 to li_elem_ct
// Adjust element proportion.
if not lb_found [ li_elem_ctr ] then
lc_total_purity &
= ac_total_purity [ li_elem_ctr ]
ac_total_purity [ li_elem_ctr ] &
= ( lc_total_purity &
* lc_prev_total_weight ) &
/ ( lc_prev_piece_weight &
+ lc_prev_total_weight )
end if
next
end if
close piece_cursor;
destroy ldsa_piece
return
Even with the extra logic, the code of Listing 5 runs twenty times faster than Listing 3. In the real application there was a lot of other stuff going on so the improvement there was “only” about 10 to 1. Nevertheless, that was more than enough to change response time from minutes to seconds, from hopeless to acceptable.